According to Wiki, feature scaling is a method used to standardize the range of independent variables or features data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step.
Rescaling. The simplest method is to rescale the range of features such that all the values be included in [0, 1] or [-1, 1]:
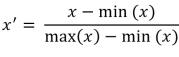
Standardization. Makes the values of each feature in the date have 0 mean. This is typically done by calculating standard scores. The general method of calculation is to determine the distribution mean and standard deviation for each feature. Next we subtract the mean from each feature. Then we divide the values (mean is already subtracted) of each feature by its standard deviation.
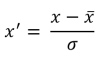
Scaling to unit length. This method scales the components of a feature vector such that the complete vector has length one. This usually means dividing each component by the Euclidean length of the vector.
![]()
Example. Let’s take an example. We have as a dependent variable the price of apartments in London. Our exogenous variables are:
x1 = size (0-2000 feet2)
x2 = number of bedrooms (1-5)
We can scale these two features as follows:
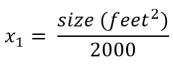
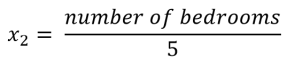
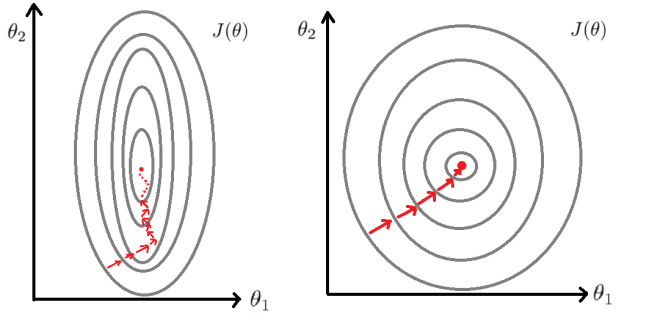
In the image above, first graph represents the way of the cost function to the global minimum before using feature scaling on data and the second one is the representation after using feature scaling. As it can be seen from the above graphs, in the first instance it takes much harder time for cost function to gain the global minimum.

[…] we choose our features like this, then feature scaling becomes increasingly important. Therefore, […]
LikeLike
[…] understanding multiple normal equation. It is good to specify that if you are using this method, feature scaling is not […]
LikeLike